Let's go to "Data Guard Performance" page to monitor Data Guard performance.
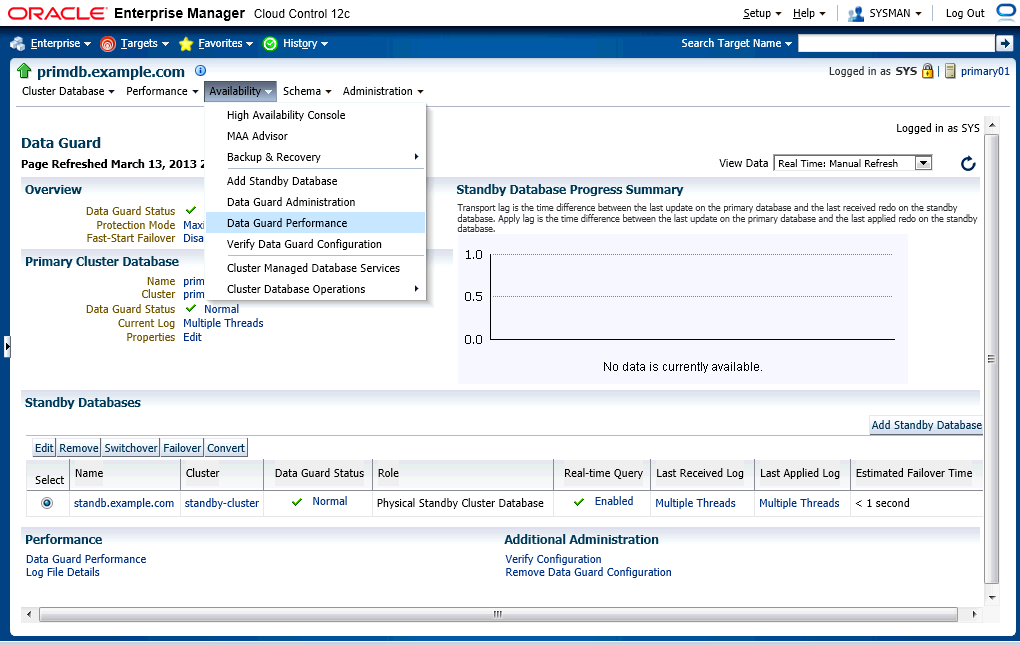
The page shows the status of overall, redo generation, transportation and apply. Let's scroll down to the bottom.
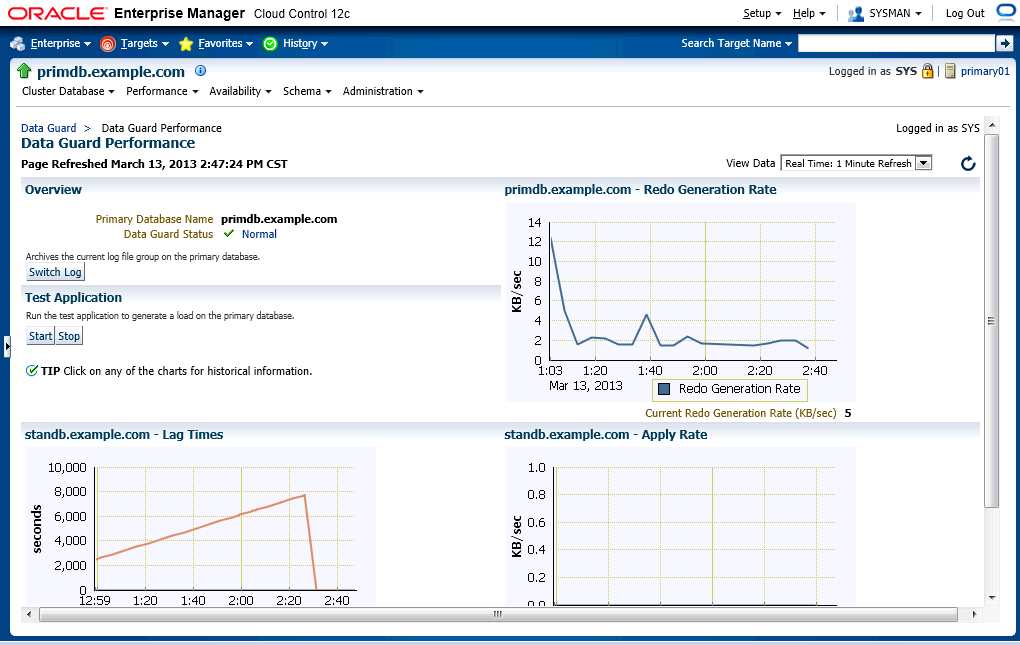
The chart of apply lag time shows there was a lag around 2:30 pm and a sharp drop after solving that.
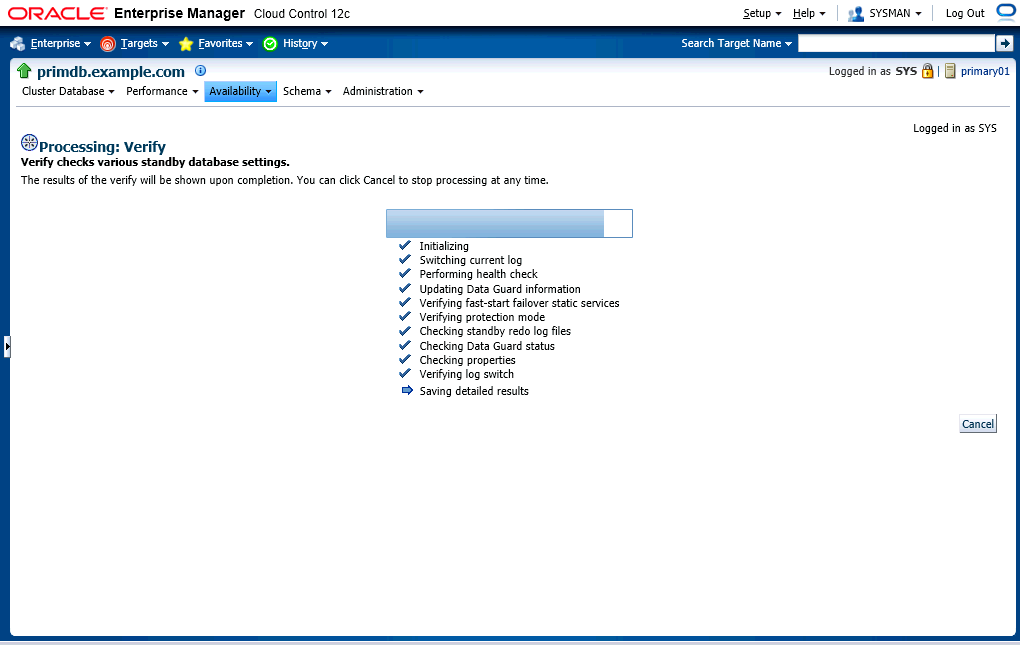
Let's go to "Verify Data Guard Configuration" page.
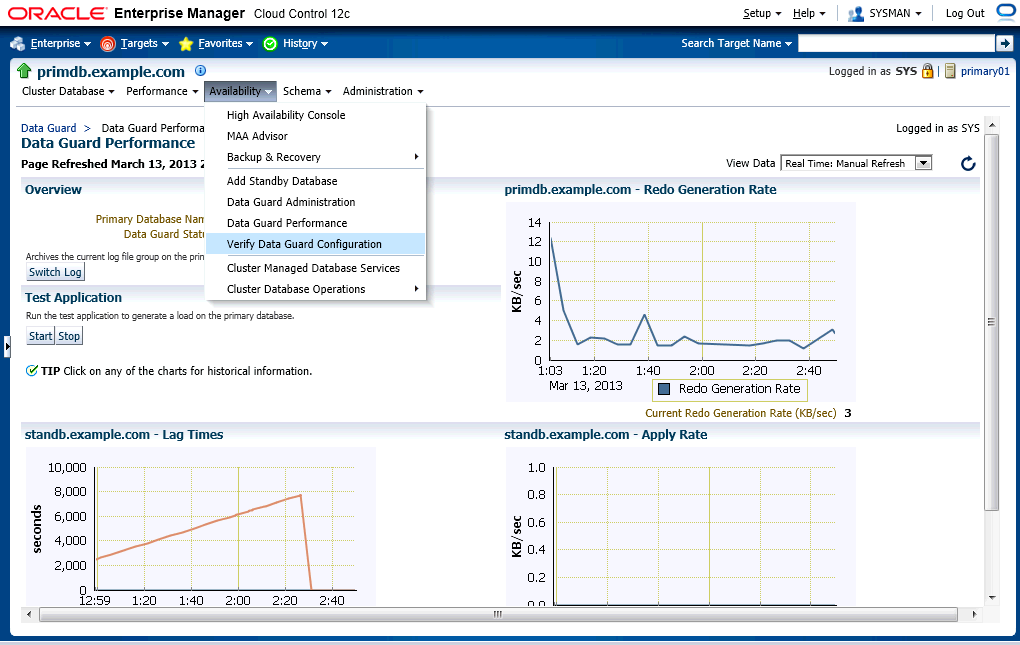
I don't think this configuration is same as the broker configuration.
The verification is in proceed.
The result is some kinds of advisers, which recommends we should create standby redo logs to facilitate Data Guard.
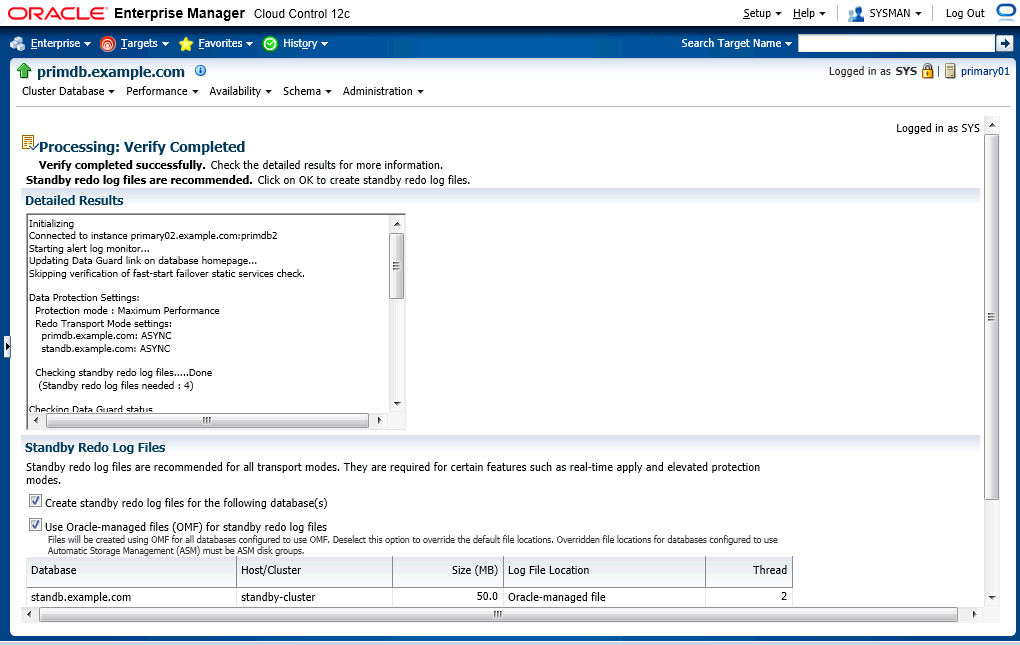
But I do have standby redo logs in both primary and standby cluster databases. I don't need more standby redo logs.
[oracle@primary01 ~]$ sqlplus / as sysdba
...
SQL> select GROUP#, THREAD#, SEQUENCE#, BYTES from v$standby_log;
GROUP# THREAD# SEQUENCE# BYTES
---------- ---------- ---------- ----------
5 1 0 52428800
6 1 0 52428800
7 2 0 52428800
8 2 0 52428800
....
[oracle@standby01 ~]$ sqlplus / as sysdba
...
GROUP# THREAD# SEQUENCE# BYTES
---------- ---------- ---------- ----------
5 1 0 52428800
6 1 110 52428800
7 2 109 52428800
8 2 0 52428800However, I accept the recommendation and click "OK" button below to create standby redo logs.
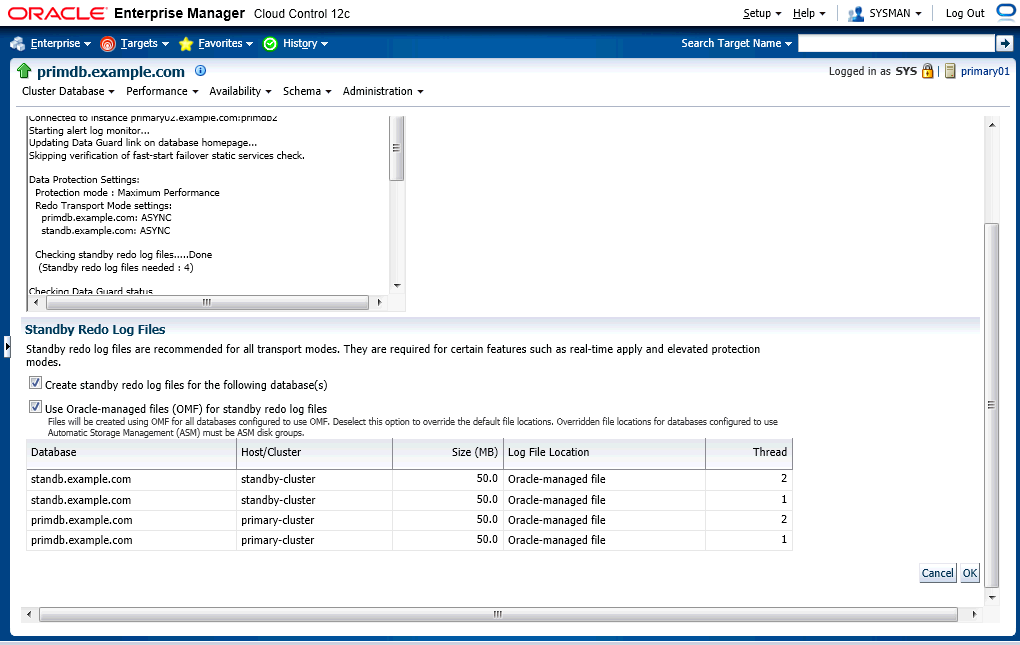
Now, I got two more standby redo logs in standby cluster database.
SQL> /
GROUP# THREAD# SEQUENCE# BYTES
---------- ---------- ---------- ----------
5 1 116 52428800
6 1 0 52428800
7 2 0 52428800
8 2 115 52428800
9 2 0 52428800
10 1 0 52428800
6 rows selected.Why would the function of "Verify Data Guard Configuration" make such confusing recommendation? Is it a bug or something?